Robot Learning meets Formal Specifications: Designing Safer Embedded Software in the age of AI
Introduction
There is considerable interest to use modules developed using deep learning in embedded software for complex cyber-physical systems (CPS) such as automobiles, aerial vehicles, and robots. Traditionally, such CPS applications have relied on human supervision for defining high-level plans, while using automated control techniques for lower level tasks; e.g., humans driving automobiles or pilots manually flying airplanes. Control engineering has striven to achieve full autonomy for such systems by relieving humans of the burden of supervision, and the excitement about autonomy has reached a fever pitch due to applications like self-driving cars. Though rule-based and model-based control algorithms for self-driving cars are still prevalent, there has been increasing interest in deep reinforcement learning (deep RL) for planning and decision-making not only in autonomous driving but also in other robotic domains. However, the use of deep RL should be accompanied by ample caution: such CPS applications are safety-critical, and naive application of deep RL is infamous for producing fragile control policies that cannot be debugged in a conventional manner. On the other hand, software engineering practices including formal approaches for specification, debugging and verification have seen many successes in designing safety-critical systems. In this article, we are interested in understanding how we can systematically develop control policies using deep RL following a specification-guided process.
What is Deep-RL?
The field of RL evolved from optimal control. RL provides algorithms to obtain control policies to regulate the system behavior in the presence of a stochastic environment. In RL, the decision-making entity is called an agent, and the objective of an RL algorithm is to learn a control policy for the agent. The agent state at a given time t (denoted St) changes when it takes an action At, upon which the environment gives it some reward Rt+1, and transitions it to some next state St+1, according to some probability distribution. Classical RL algorithms assume that the environment and the agent form a Markov Decision Process (MDP), i.e. where the probability distribution on the next state (and reward) is dependent only on the current state. These algorithms give efficient solutions to the optimal policy, i.e., one that maximizes the expected return (e.g. the discounted sum of rewards) from an agent behavior, typically using a dynamic programming approach to find the value of each state in the MDP and optimal policy. The value of a state is the expected payoff from a behavior starting at that state. As modeling complex real-world environments as MDPs is difficult, model-free RL techniques learn approximations of the value function or the optimal policy using simulations. For continuous state and action spaces such methods are not feasible, leading to the development of deep reinforcement learning (Deep RL) where the value functions or the policy maps are instead represented using deep neural networks (DNNs).
Unfortunately, poorly designed rewards can have catastrophic consequences in safety-critical systems.
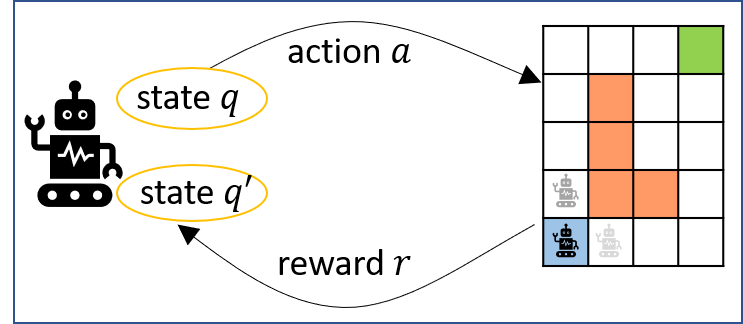
Fig. 1: Reinforcement Learning
Specification-guided RL
Independent of the type of the RL algorithm used, an important stipulation is that the designer defines state-based local rewards that can be interpreted as an implicit specification for the system. The assumption is that behaviors that maximize the expected rewards are desirable. Unfortunately, poorly designed rewards can have catastrophic consequences in safety-critical systems. A deep RL algorithm can learn to hack the reward function (called reward hacking); where the agent policy maximizes the expected returns, but the corresponding behaviors are either undesirable or unsafe. For example, consider a cleaning robot that alternates between sensing the dirtiness of the environment and performing the cleaning task. Consider the reward function that sounds perfectly plausible: the robot gets the maximum reward when it no longer senses dirt in the environment. A reward hack is for the robot to never use its sensing mode. The robot learns that if it cannot see the mess, there is no mess!
To mitigate this problem, the RL community has invested effort into reward engineering or reward shaping in two different ways: (1) by adding extra information in the reward by means of potential functions, and (2) engineering rewards by inferring them from expert demonstrations. Carefully constructed rewards or demonstrations are indirect ways of indicating the desired behavior of the system. In contrast, the formal methods community has a long history of using explicit logical specifications to articulate desired system behavior. In the 70s, Amir Pnueli introduced Linear Temporal Logic (LTL) as a specification language for reactive programs. Signal Temporal Logic (STL) was invented by Maler and Nickovic to serve as a specification language for mixed signal circuits, and has recently emerged as a dominant specification language in CPS. Atomic STL formulas consist of signal predicates of the form f(x)>c, f(x) ≤ c, etc., where x is a signal variable (mapping each time point to some value), f is some function, and c is a constant. STL formulas are recursively constructed through Boolean combinations of smaller STL formulas using logical connectives such as and, or, not, and time-scoped temporal operators such as always (G), eventually (F), until (U). For example, the following formula indicates that whenever the dirtiness exceeds a certain threshold , the robot must clean within the next 5 minutes, and the robot must sense dirt once every 45 minutes. Observe that to satisfy this formula the robot cannot never sense dirt.
G[0,∞)((sensed_dirtiness > θ) ⇒ F[0,5] (mode=clean)) ∧
G[0,∞)F[0,45] (mode=sense_dirt)
Reward Shaping from Temporal Logic Specifications. The ability to translate LTL specifications into ω-regular automata as monitors has been used extensively to generate rewards for RL agents. In this scheme, MDP models of the system are composed with the specification automaton to track progress to task completion and is in-turn used to reward the agent. Fu and Topcu presented a Probably Approximately Correct (PAC) learning algorithm where they learn the transitions of an MDP composed with a Deterministic Rabin Automaton (DRA), a kind of an ω-regular automaton, while simultaneously learning a policy that is provably correct in the original finite MDP. Recent works by Sadigh et al. and Hahn et al. formulate model-free RL algorithms that use ω-regular automata to directly generate rewards. Basically, an agent receives a reward whenever it visits an accepting state in a DRA, while in the latter, this reward function is probabilistically defined on a Limit-Deterministic Buchi Automaton (LDBA). Similarly, Hassanbeig et al. use the same type of LDBA to construct “frontier sets”: regions in the MDP that need to be visited at any given time in an episode, and reward the agent for reaching such frontier sets. To summarize, the main idea is to construct automata to monitor the LTL specifications, and then use rewards to guide the RL procedure towards the end components of either the explicitly constructed or the implicit product between the MDP and the specification automaton.
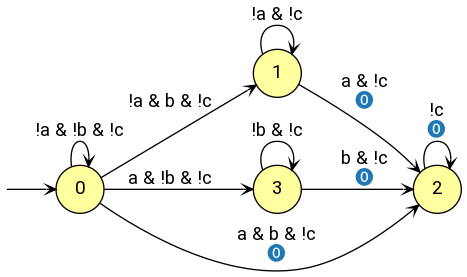
Fig 2: An LDBA that monitors the specification “Eventually complete task a and task b while avoiding some state c.” The goal of an RL algorithm will be to visit the transitions labelled ‘(0)’ infinitely often, i.e., get to the state labelled ‘2’ and stay there.
There is also recent work on using RL to guide a system towards satisfying STL specifications. STL-based approaches for RL have largely eschewed automata-based methods, but instead use the quantitative semantics for STL to compute reward signals. These semantics define a robust satisfaction value (a.k.a. robustness) that quantifies how well a given trace satisfies a given STL formula. Aksaray et al., present a modification of the class Q-learning algorithm that uses the STL robustness of a temporal-MDP to generate rewards. Generating this temporal-MDP requires enumeration of possible future states, making the size of the state space exponential in the time horizon of the STL specification. Xi et al. present a Monte-Carlo method that computes the robustness of a policy after each simulated episode, but this has the same disadvantages as Monte-Carlo methods where the number of samples required to find good trajectories in the system is large. In Balakrishnan et al., we present a model-free deep RL algorithm similar to N-step Temporal Difference-based RL algorithms, where robustness is approximated for some finite future and actions taken at the start of the rollout are rewarded for the finite future.
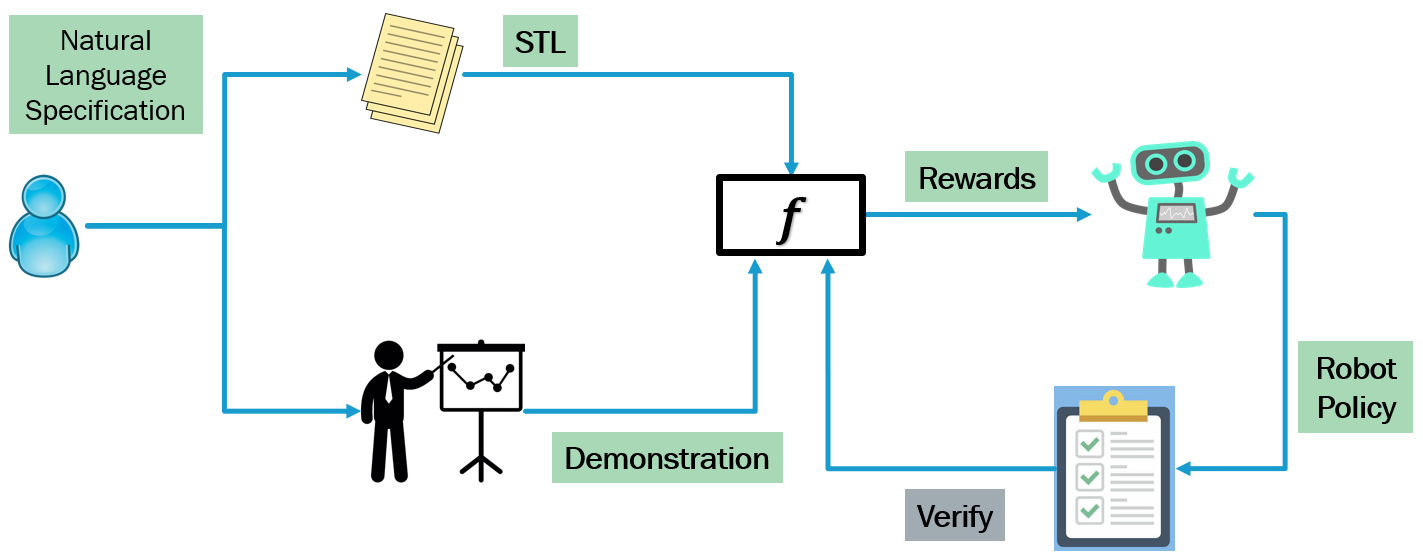
Fig. 3: Proposed Framework for Learning from Demonstrations and Specs
Specification-guided learning from demonstrations
Till now, we have discussed how RL can be combined with formal logic in scenarios where rewards are inferred from the specifications. However, rewards obtained from logical specifications can be sparse and may lead to slow convergence. Learning-from-demonstrations (LfD) is a paradigm for learning where human demonstrations of desired behavior are used to learn the control policy. High level specifications can be viewed as specifying what an autonomous system should do, while human demonstrations can be viewed as partial policies showing how to accomplish the high-level specifications. In real-world, demonstrations are scarce, seldom optimal and are susceptible to user fallibility, stochasticity in the environment, or because the task may be simply hard for the user to demonstrate! Control policies inferred from incomplete, incorrect or sub-optimal demonstrations may perform unsafe or undesirable actions as shown by Hussein et al. LfD techniques have thus been criticized for lacking robustness . Furthermore, as Ravichandar et al. argue, demonstrations are not always equal: some are a better indicator of the desired behavior than others, and the expertise of the demonstrator determines the quality of the demonstration. Ho et al. show that there are differences when people intentionally teach a task versus simply doing the task. Finally, safety conditions cannot be explicitly specified by demonstrations, and safely providing a demonstration requires skill.
In Puranic et al., we have recently shown how we can imbue LfD techniques with formal reasoning. The main idea in our approach is to use STL specifications to serve as high-level mission specifications. User demonstrations are ranked using the given STL specifications — this allows us to prioritize demonstrations that are complete and correct. However, our technique can still learn from incomplete and incorrect demonstrations, because even a negative example gives some information about where a positive behavior may lie through the use of STL robustness. Our approach has shown promise on a number of standard RL benchmarks especially compared to state of the art approaches in Inverse Reinforcement Learning (such as max causal entropy IRL). We see that augmenting the LfD task with formal specifications can bring up to two orders of magnitude savings in sample complexity (number of demonstrations required) for some benchmarks. This could pave the way for robotic designers to take formal specifications seriously. They not only help characterize the desired behavior of the system in a rigorous manner (for the purpose of testing/verification), but also fundamentally help design controllers that are safer in a smaller number of design iterations!
Summary
In this article, we introduced the area of RL and deep RL for automatically synthesizing controllers for complex cyber-physical systems guided by specifications expressed in temporal logic, possibly along with user demonstrations. We conclude by remarking that the techniques presented herein have a lot of promise to pave the way for safer autonomous design while still leveraging the power of deep learning.
The author thanks Anand Balakrishnan and Aniruddh G. Puranic for their assistance in creating this post.
Author bio: Jyotirmoy V. Deshmukh is an assistant professor in the Computer Science at the University of Southern California, Los Angeles, USA. Before joining USC, Jyo worked as a Principal Engineer at Toyota R&D. His research interests are in the broad area of analysis, design, verification and synthesis of cyber-physical systems, including those that use machine learning and AI-based algorithms.
Disclaimer: Any views or opinions represented in this blog are personal, belong solely to the blog post authors and do not represent those of ACM SIGBED or its parent organization, ACM.