Knowledge is Power. The Case for Profile-driven Resource Management in Complex Systems

Take 100 lines of C code and a hardware platform. How long will it take for the hardware to execute the code? Being able to construct an answer to this question in the scope of real-time systems is akin to solving one of the Millenium Prize Problems. Of course, the first instinct is to wonder if any loop in the code makes this question equivalent to solving the halting problem. Yet, the problem stands even if we assume a perfectly sequential list of instructions. One could even make the (not so) provocative statement that predicting the timing of a single instruction can be challenging.
The roots of uncertainty.
Indeed, apart from having to disentangle possible data hazards at the level of CPU pipeline, the instruction itself to be executed might incur a multi-level cache miss. If this is a system with virtual memory, the instruction address will undergo a TLB lookup and might result in a miss at this stage, triggering a page-table walk. The walk might be several levels deep, depending on the granule of memory translation and whether or not a hypervisor is active in the system. Each main memory access triggered by this chain of events — including the original instruction fetch — will typically need to cross a hierarchy of interconnects. Once each memory request reaches the main memory controller, it is translated into a set of DRAM commands generated ad-hoc to respect the timing requirements of DRAM cells and considering the other transactions already queued, or arriving within a short time horizon after the one under analysis. Once the CPU receives the response, the memory instruction can finally be decoded. And if that instruction happens to be a memory instruction, the whole process might be repeated to access the data location.
The astounding number of might’s in the paragraph above should give away the nature of the problem in accurately predicting the timing of instructions in modern platforms. That is, one would need to track an awfully large machine state to perform an accurate analysis. Also, the machine state often evolves according to not-fully-understood interactions between multiple components of the micro-architecture. Furthermore, the state can suddenly change due to the occurrence of asynchronous events—e.g. I/O-related interrupts. And of course, the state of any shared component of the memory hierarchy is continuously (and asynchronously) affected by any other processor with memory-mastering capabilities — e.g. another CPU, a DMA-capable I/O device, or any accelerator.
Having to give up on computing the exact time to execute a (memory) instruction, the next best thing is computing an upper bound on the worst case. And in that regard, static analysis methods have come a long way. Toolkits such as AbsInt aiT and HEPTANE implement the latest advancements in abstract interpretation-based static analysis for worst-case execution time (WCET) computation. They achieve incredible performance on a number of simpler platforms with widespread application in industrial settings. But unfortunately, the development of the theory behind static analysis has simply been unable to keep up with the rate at which architectural features from the general-purpose computing world have been introduced into embedded systems.
Can’t we just pick well-behaved hardware?
We can divide hardware platforms into two categories. The first being the set of platforms that are tractable through static analysis methodologies and tools. Thanks to the continued dedication of the community in improving these methods, this set encompasses an incredible variety of microcontrollers. Conversely, the second set is comprised of platforms where static analysis approaches fall short — perhaps just in terms of analysis runtime for any realistic workload. So why are we bothering with trying to design real-time systems with platforms in the second category? In one word: expectations.
Practically speaking, when a new product is designed — especially in volume markets — the emphasis in the platform selection phase goes into the per-dollar computation capacity of the system as opposed to its tractability from a temporal analysis standpoint. Another way to see it is that under the peer pressure of consolidating smart systems, Company X will pick the platform where the “latest and greatest” AI workload will run. That comes with some hope that if enough manpower is thrown at the problem, the temporal behavior can be kept under control. The alternative is a system with impeccable predictability and yet hopelessly incapable of handling expectedly heavy workloads. Therefore, it comes as no surprise that a business-driven platform selection is based on vague indicators of capacity such as FLOPS, peak main memory bandwidth, number of CPUs, number/nominal performance of specialized accelerators. What is blissfully unknown at platform selection time is proper system bottleneck analysis, which is strictly dependent on the workload.
The problem of determining tight estimates of the execution time is further exacerbated when applications are deployed on a platform with multiple cores sharing the same resources like the cache, interconnect, and main memory. Add complex SoCs with accelerators to the mix and the problem only gets worse. Memory contention can cause a slowdown in critical applications that is anywhere between 2x and 14x. Such performance degradation is nothing that can be hidden away with good scheduling and mechanisms are needed to bound the (worst-case) impact of contention through intelligent resource management.
Can’t we just partition resources or provide dedicated resources?
The community has not been silent on the problem of predictable execution on modern platforms. On the contrary, resource partitioning, i.e. trying to completely avoid or strictly manage access to shared hardware, has been seen as a promising strategy. For instance, the shared last-level cache in multicore platforms is known to be a major hindrance against tight execution time bounds. A solution could be partitioning the cache on a per-core/per-application basis. Software (e.g. cache coloring) and hardware (e.g. way-based partitioning) mechanisms are available and have been extensively studied.
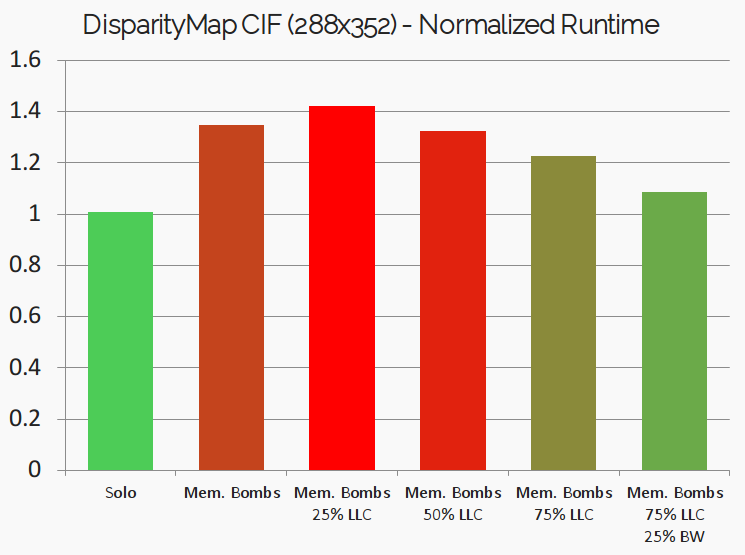
To better understand the tradeoffs of cache-coloring, let’s consider a simple experiment. Here we use the DisparityMap benchmark from the San Diego Vision Benchmarks Suite (SD-VBS). The algorithm carries out depth perception, by computing the relative positions of objects in a scene captured by stereo cameras. The algorithm takes as input a pair of images and the output is a gray-scale image where the objects closest to the camera are colored brighter and the objects farther away are colored darker. The experiment reported in Figure 1 was carried on a Xilinx ZCU102 platform. For the baseline execution time, we first run the benchmark alone on the platform. Next, we use the Jailhouse-RT hypervisor to induce cache and memory contention by co-running it with specially engineered “Memory Bombs” deployed in their own self-contained virtual machines. As expected, this led to an increased execution time (about 33%) compared to the baseline as seen in the above figure.
Suspecting that cache contention may be the culprit for the degradation, we leverage cache coloring to dedicate 25% of the cache to the DisparityMap benchmark. Not only does the application performance not improve, but it gets worse! Dedicating half of the entire cache only brings marginal improvement. Some visible improvements are only visible with 75% of the total shared cache dedicated to the benchmark. But why? After all, the benchmark is processing a mere ~100k pixels. Indeed the root of many of the issues with partitioning is that we are fundamentally blind with respect to the cache usage pattern of our applications.
Therefore, while the fundamental ability to perform resource partitioning is absolutely crucial, this capability alone is not enough to implement good resource management. In general, any static partitioning scheme leads to lower resource utilization, since no other application can make use of the resource; Further, resource usage in applications varies over time and it often depends on the inputs. The takeaway is that solid and well-understood partitioning primitives are an absolute must in modern RTOS, but that their tuning needs to be accompanied by accurate application profiling.
Profile-driven resource management: big-data on a micro-scale
A prerequisite to effective resource management is the ability to analyze applications and understand their resource usage patterns. In a word: profiling. Profiling involves measuring key resource usage metrics like the cache footprint, instruction cycles, and memory bandwidth usage over the application lifetime and progress. Once these parameters are derived for different applications, key decisions on resource allocation — like reserving processor time, partitioning the cache, and/or allocating the required main memory bandwidth — can be performed to meet explicit application requirements. Profiling represents a substantial refinement of measurement-driven approaches, where fine-grained knowledge of the interaction between applications and the platform is collected and leveraged.
But the wonderful promises that come with profiling and profile-driven management are not without challenges. On the profiling front, most modern processors provide some performance monitoring infrastructure to acquire key metrics — e.g., retired instructions, number of cache misses or branch mispredictions. But unfortunately, these are not immediately sufficient to understand more complex metrics like determining the working set-size of an application, or how the usage of hardware resources evolves as an application progresses. Furthermore, for profiling techniques to be effective, they must meet the conflicting requirements of being minimally intrusive to the application under analysis while also being able to deliver fine-grained measurements by sampling fast enough.


In our work, we have been exploring novel possible approaches to profiling. With CacheFlow, we explored the ability to read the content of CPU caches to extract exactly which portion of an application addressing space is cached as the application progresses, as shown in Figure 2. In a similar spirit, the BBProf toolkit provides an approach to rank virtual memory pages of an application, based on the speedup in the overall application’s execution time achieved by caching each of them. An example of this analysis is provided in Figure 3. The technique can help identify the working-set of applications and shed light into the relationships that tie memory objects’ access time and overall runtime. Focusing on full-system main memory bandwidth, our E-WarP profiling infrastructure enables the collection of a dense timeline of activity generated by an application under analysis that can also use hardware accelerators.
In all cases, we demonstrated that the profiling information collected offline can truly guide in designing effective resource allocation strategies and also refine the expectation on the runtime of applications once they are composed together. While these are some successful attempts at rethinking profiling as a system commodity, the road ahead is littered with challenges. Profiling in modern platforms is a microcosm encompassing many of the typical big-data processing problems but that need to be solved at the scale of microseconds. So let’s break down a possible path from today’s state-of-the-art to our RTOSes of tomorrow.
Step 1. Offline Profiling + Profile-driven Partitioning
For a system with static, well-known time-critical applications, resource partitioning can be guided by the information gathered during an offline profiling phase. In this scenario, each application is profiled in isolation before deployment to derive its resource usage characteristics. The system designer can then allocate resources to the different workloads accordingly, in order to meet performance requirements and to ensure temporal isolation. Such a method comprises two different aspects: the allocation of resources over time and a strategy on how these resources are used by the applications. Using the caching example above, the ranking of virtual memory pages can, for instance, be used to determine the cache size assigned to an application via cache coloring and decide which memory pages are cached to make the best use of the available cache partition.
Step 2. Offline Profiling + Dynamic Profile-driven Management
Unfortunately, truly complex systems do not consist of a fixed set of known applications that run statically but are typically characterized by applications that are activated or deactivated in response to changes in the environment and even include dynamically entering or exiting applications. In this case, it is not feasible to perform an efficient static resource partitioning at design time. Instead, the system must be capable of adjusting the resource management online as the system undergoes changes in its state.
To achieve this vision, two challenges need to be addressed. The first is accountability. That is, the ability to correlate the progress of applications with the expected and measured consumption of system resources. Methods that can be general enough to capture the complex semantics of modern applications, and that can be lightweight enough to be incorporated in an RTOS are certainly the holy grail of this vision. Secondly, on the resource management front, platforms shall provide sufficient flexibility in changing resource allocations on the fly. To some extent, this requirement is being understood better and better with newer platforms. The most notable attempts are perhaps the much-advertised Intel Resource Director Technology (RDT) and the much-anticipated ARM Memory System Resource Partitioning (MPAM). In other cases, it has been shown that low-overhead reconfiguration of resource partitioning can be achieved in embedded platforms with partially reprogrammable logic (FPGA).
Step 3. Online Profiling + Dynamic Profile-driven Management
Successfully tackling the aforementioned steps is foundational to evolve our RTOSes and hardware platforms to understand applications and to use the acquired knowledge for informed system management. The last leap towards truly self-aware systems is the ability to collect online profiles for applications never seen before, and that of refining previously collected information as new runs are observed. For critical applications, offline profiling can still be provided but considered only as a pessimistically safe envelope to be refined online.
In this part of the vision, the goal is to minimize the amount of pre-acquired knowledge necessary for system integration. The immediate benefit is the ability to rapidly push modular updates to deployed systems while maintaining operational guarantees. The idea is that with online profiling, the system integrator can dynamically account for the resource usage of such modular updates (or newer applications that could not be profiled earlier), and adjust resource allocation policies dynamically to ensure that timing guarantees of existing time-critical applications are not disturbed. In addition, many modern applications (e.g. video/radar processing, path planning, etc.) have varying resource requirements depending on the input data received (say for example depending on the number of detected objects at runtime), and a detailed offline profile covering the resource requirements under all scenarios is infeasible or prohibitively expensive to achieve. For such applications, a prerequisite to effective resource allocations at runtime is being able to continuously monitor the resource usage and tune resource allocations accordingly. Additionally, deeper insights provided by online profiling regarding the combined resource usage patterns of co-executing applications at runtime can help adapt resource allocation policies on the fly, leading to improved system utilization.
Outlook
Accomplishing this vision of online profiling combined with dynamic resource management calls for a tight-loop interaction between performance reporting hardware infrastructure and software layers. Ideally the ability to program performance metrics, targets, and events at the level of memory and I/O hierarchy might be necessary to fully accomplish this vision. In particular, the key will be the ability to define off-band channels for the acquisition of performance metrics in ways that can be directly related to application-level progress — i.e. control-flow events. Is a programmable memory hierarchy a far-fetched idea? Time will certainly tell. But there is a growing tangible consensus that revising the strict compute-centric interface of memory subsystems might be overdue. We are just advocating for temporal properties to be part of the design, not of the patch.
 Author bio: Renato Mancuso is an assistant professor in the Computer Science Department at Boston University. Renato received his Ph.D. in computer science in 2017 at the University of Illinois at Urbana-Champaign. His research interests are at the intersection of high-performance cyber-physical systems and real-time operating systems. His specific focus is on techniques to perform accurate workload characterization and to enforce strong performance isolation and temporal predictability in multi-core heterogeneous systems. Renato has contributed to more than 30 peer-review publications in the field and was the recipient of multiple research awards. He is a member of the IEEE and the Information Director of the ACM SIGBED. His work is supported by the National Science Foundation and by a number of industry partners, including Red Hat Inc., Bosch GmbH, Cisco Systems Inc.
Author bio: Renato Mancuso is an assistant professor in the Computer Science Department at Boston University. Renato received his Ph.D. in computer science in 2017 at the University of Illinois at Urbana-Champaign. His research interests are at the intersection of high-performance cyber-physical systems and real-time operating systems. His specific focus is on techniques to perform accurate workload characterization and to enforce strong performance isolation and temporal predictability in multi-core heterogeneous systems. Renato has contributed to more than 30 peer-review publications in the field and was the recipient of multiple research awards. He is a member of the IEEE and the Information Director of the ACM SIGBED. His work is supported by the National Science Foundation and by a number of industry partners, including Red Hat Inc., Bosch GmbH, Cisco Systems Inc.

Author bio: Dakshina Dasari is a researcher at the Corporate Research Center, Robert Bosch GmbH. She received her Ph.D. in 2014 in the area of timing analysis of real-time embedded systems on multi-cores from the University of Porto. Her research interests include predictable execution and performance of embedded systems, design, modelling, implementation and analysis of real-time systems and computer architecture. Prior to her Ph.D. she worked in the area of networking for around 5 years with Sun Microsystems and Citrix R&D in India.

Author bio: Arne Hamann obtained his PhD in Computer Science in 2008 from the Technical University of Braunschweig, Germany. He is Chief Expert for “Distributed Intelligent Systems” at Bosch Corporate Research. Like the Bosch product portfolio, his range of activities is broad, encompassing complex embedded systems where the interaction between physical processes, hardware and software plays a major role, through to distributed IoT systems with elements of (edge) cloud computing. In the academic context, he is member of the editorial board of the ACM journal “Transactions on Cyber Physical Systems”, and regularly serves as program committee member for international conferences such as ECRTS, RTSS, RTAS, DAC, EMSOFT, and ICCPS.
Disclaimer: Any views or opinions represented in this blog are personal, belong solely to the blog post authors and do not represent those of ACM SIGBED or its parent organization, ACM.
Leave a comment